Strand NGS supports an extensive workflow for the analysis and visualization of DNA-Seq data – such as from whole genome, whole exome or targeted resequencing experiments. The workflow includes the ability to detect variants (SNPs, MNPs and short InDels), annotate them with dbSNP, and identify the effect on transcripts of non-synonymous coding SNPs. Further downstream analysis such as GO, pathway analysis, etc can be performed on the set of affected genes. Large structural variations, including large insertions, deletions, inversions, and translocations, can also be detected with paired-end or mate-paired data. In addition, copy number variations can be detected using tumor-normal pairs.
Download the DNA-Seq Highlights Guide
Download the Unique Molecular Identifier Support in DNA-Seq
Download the Large Scale Transcriptomics and Unique Molecular Identifiers Support
White paper on Fast and Accurate Variant Calling
in Strand NGS v3.0
Watch the recording on Unravelling complex mutational events in clinical cases using the power of NGS data analysis
Watch the webinar recording on Unique Molecular Identifier-powered Ultra-sensitive Variant Calling
Watch the DNA-Seq Webinar Recording
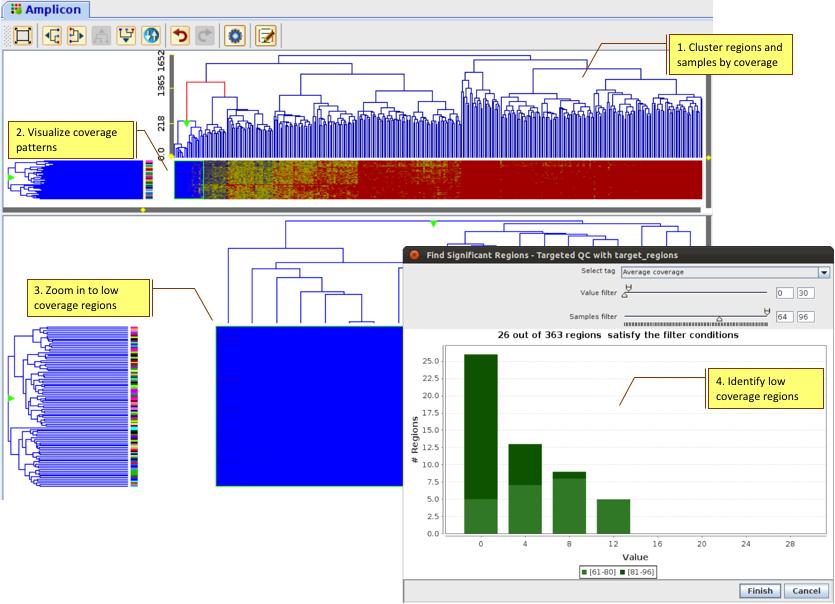
Evaluate efficacy of targeted re-sequencing, and identify regions with low coverage across samples.
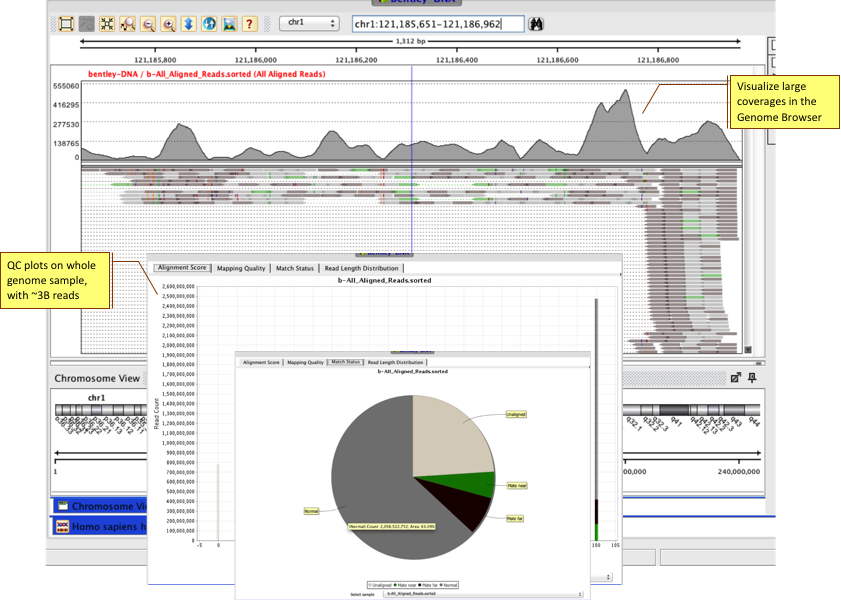
Perform Whole Genome analysis on human or other organisms on your desktop.
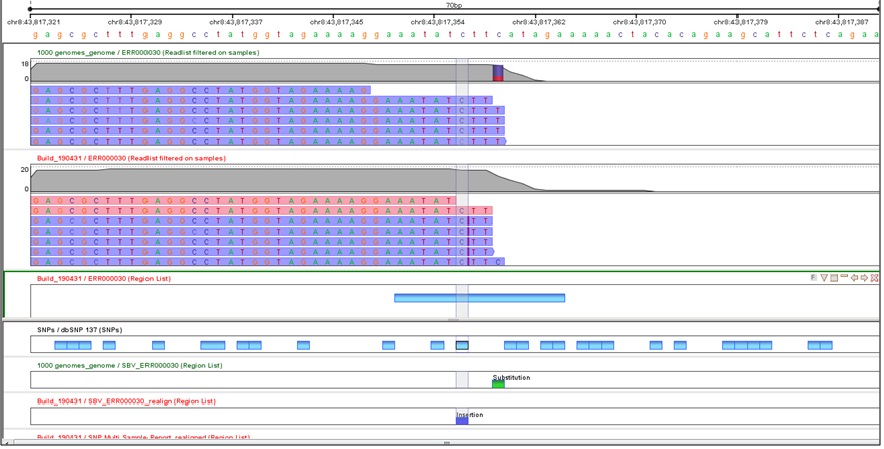
Reads with misaligned InDels due to alignment artifacts can be realigned using information from multiple reads. Helps reduce false positive variant calls.
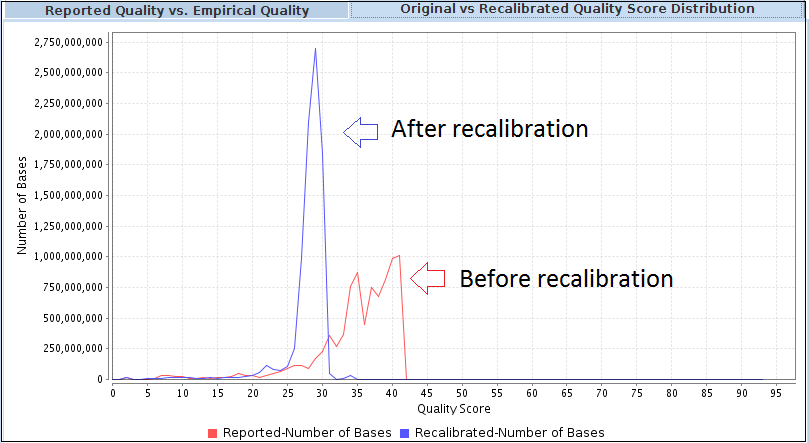
Recalibrates base quality scores using contexts such as machine cycle and di-nucleotide to reduce errors and systemic biases. Helps reduce false positive variant calls.
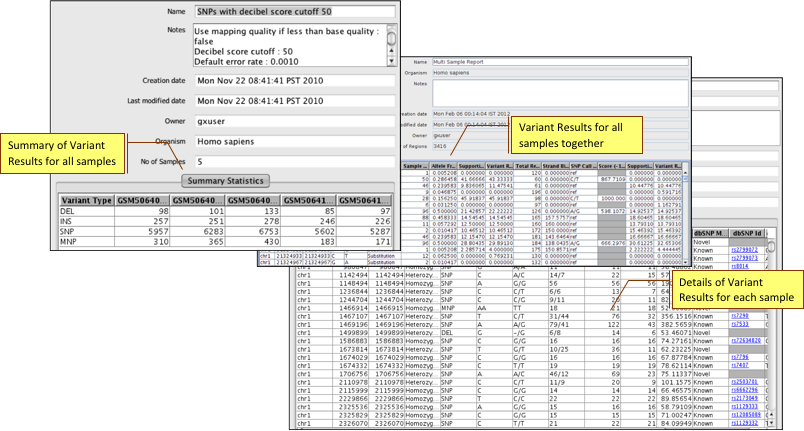
Identify homozygous and heterozygous SNPs, InDels and MNPs. Generate cumulative statistics, distributions, and rich plots. Learn more
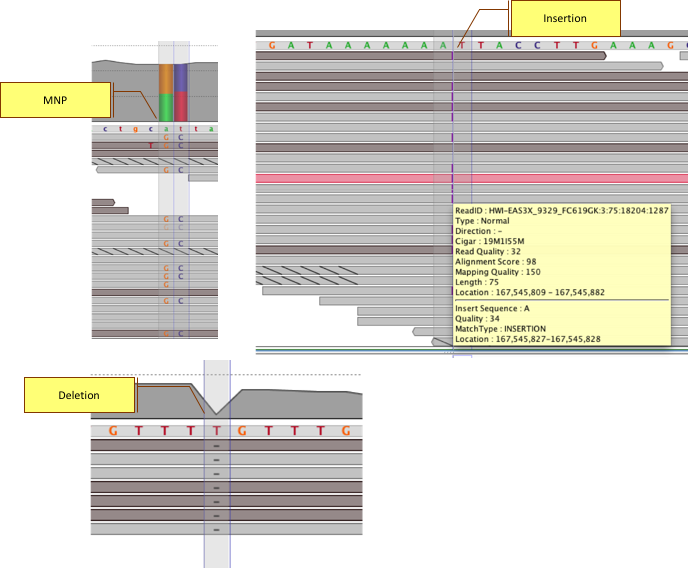
Drag and drop SNP results into the genome browser. Visualize SNPs, MNPs, and InDels along with coverage, reads as well as other annotations.
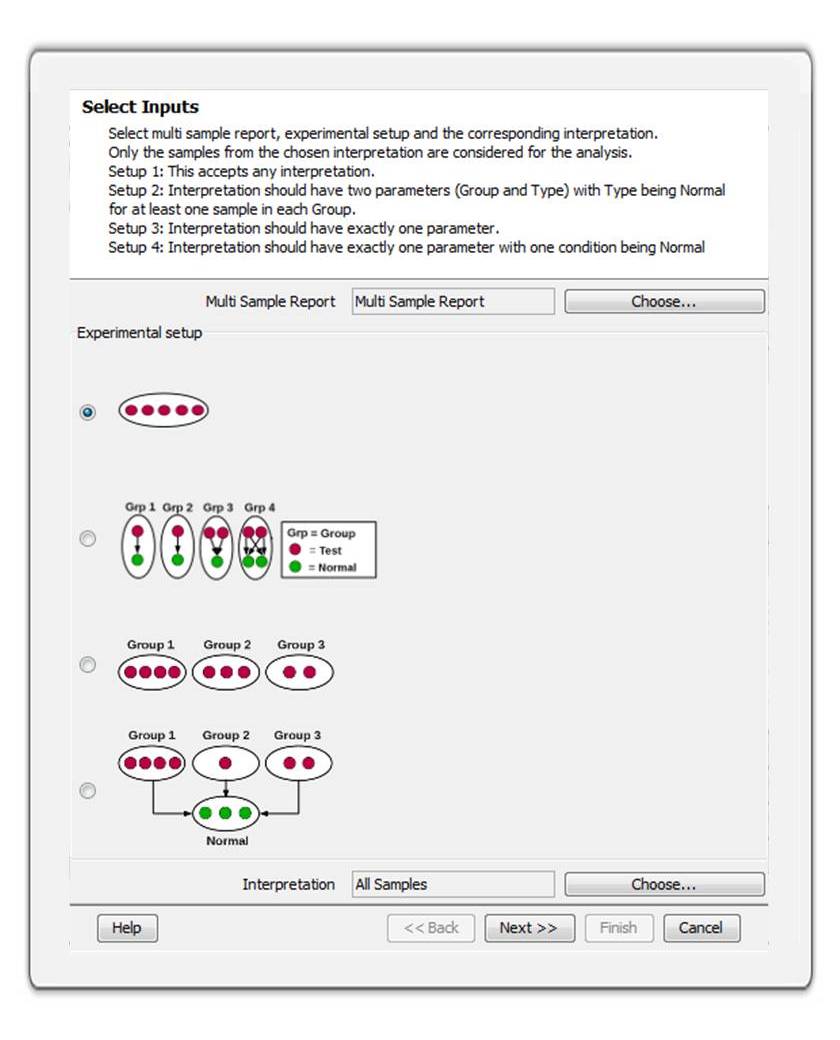
Identify significant SNPs using an intuitive filtering framework that handles multiple use cases such as tumor-normal, multi-group comparisons, low-frequency mutations, rare variant analysis, and somatic mutations.
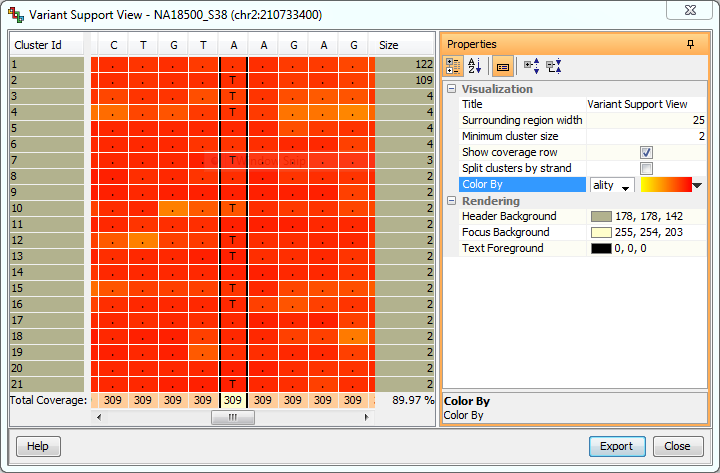
View the delta-neighbourhood of SNPs in high coverage locations. Collapse reads into clusters to quickly verify predicted SNPs. Color with base quality or mapping quality, and annotate with strand information for more insight.
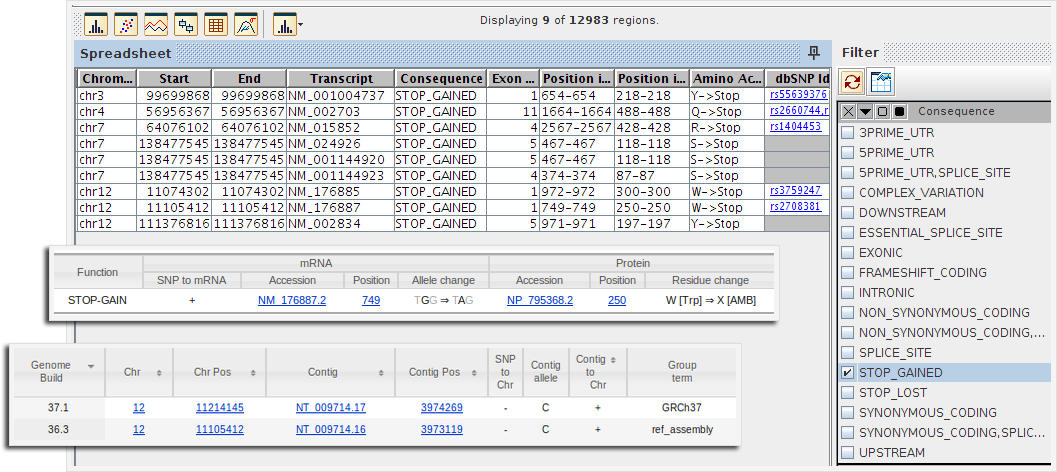
Predict the effect of SNPs on the provided transcript annotations and identify SNPs of interest. Link out to dbSNP for more details.
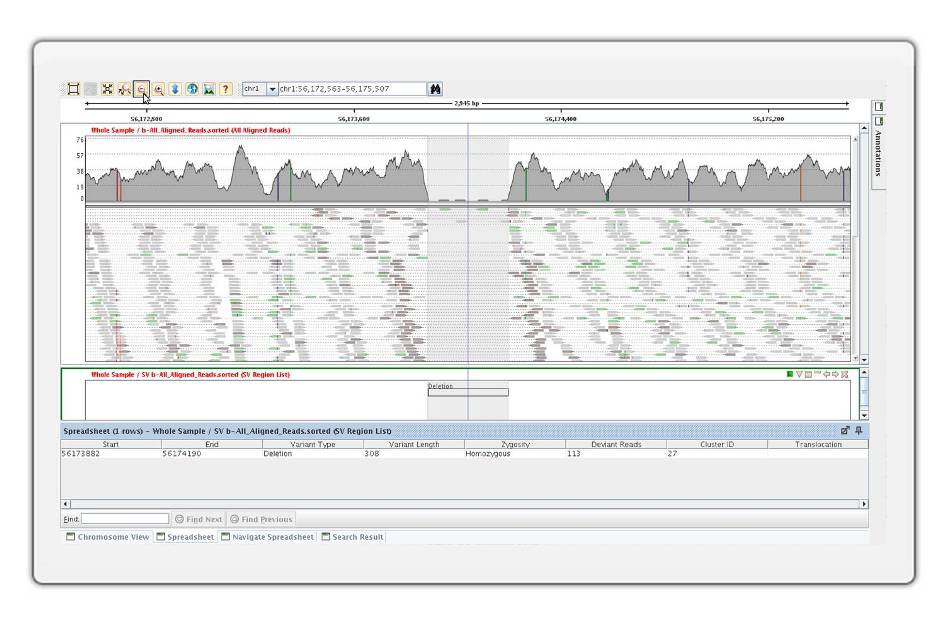
Detect structural variants in paired end data and identify large structural variants, including large deletions, insertions, inversions, and translocations. In addition, detect structural variants using split reads.
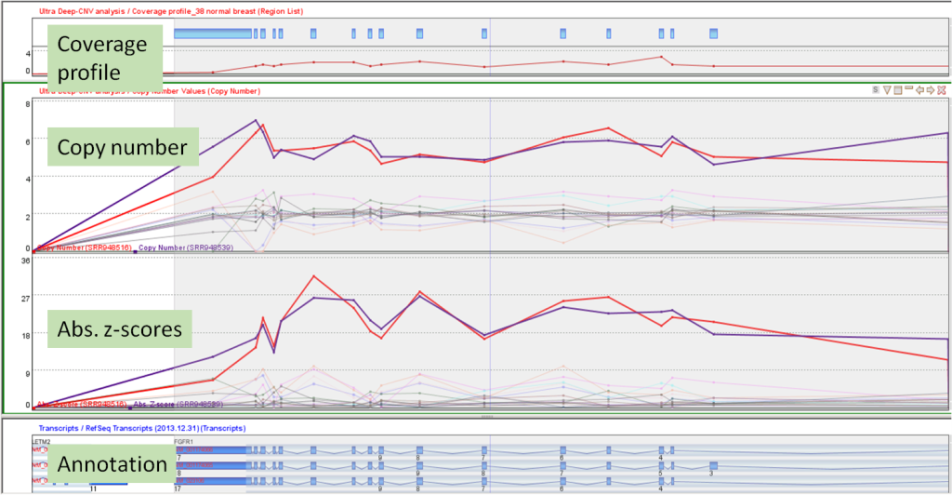
Detect CNV regions in tumor samples with respect to given normal samples. Workflow includes GC bias correction , estimation and correction for sample ploidy and normal cell contamination.
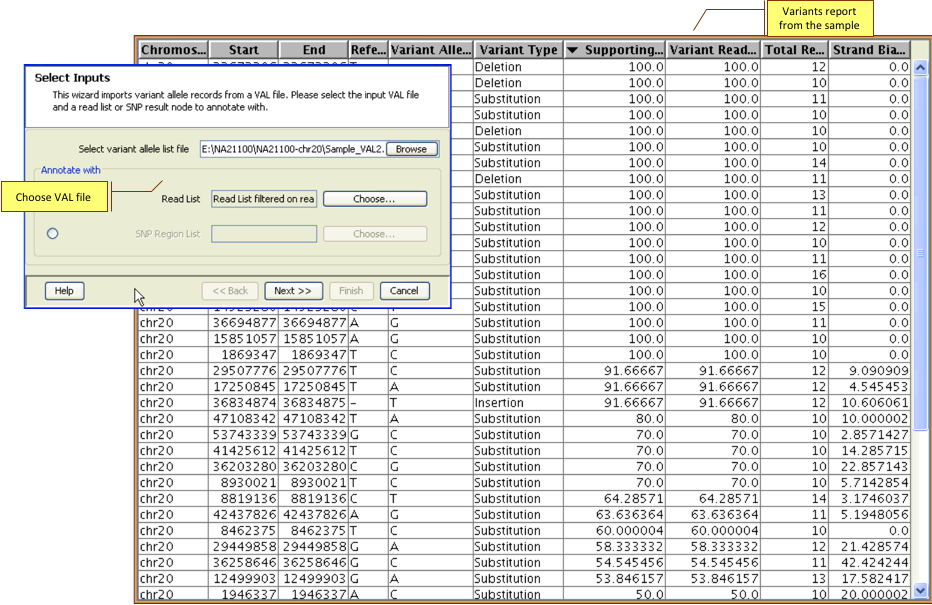
Load VCF files and perform downstream analysis in an integrated manner; load VAL files and determine occurrence of variants of interest in the sample.
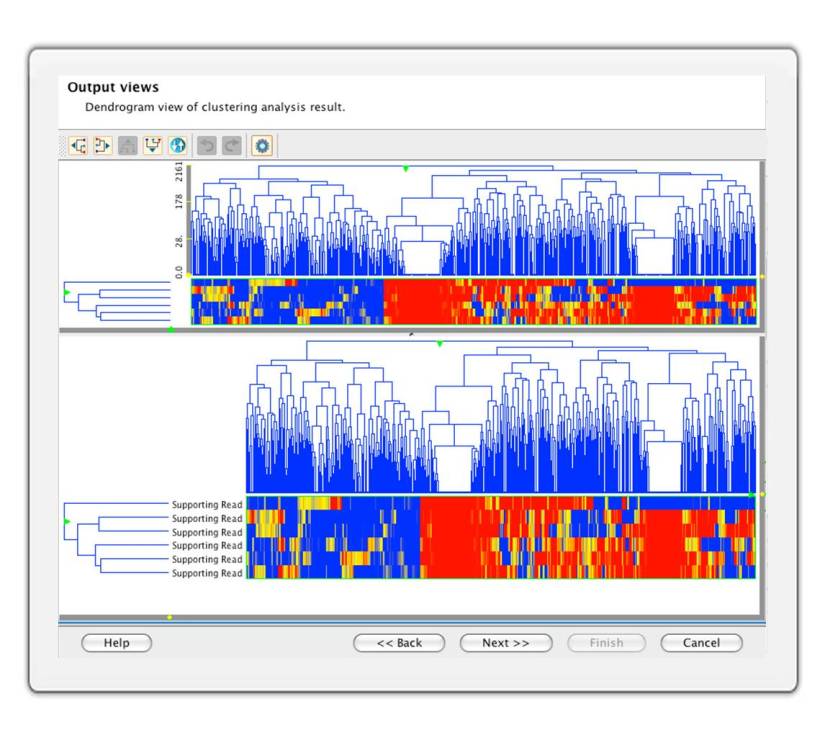
Cluster significant SNPs and samples to detect patterns such as LOH events visually.
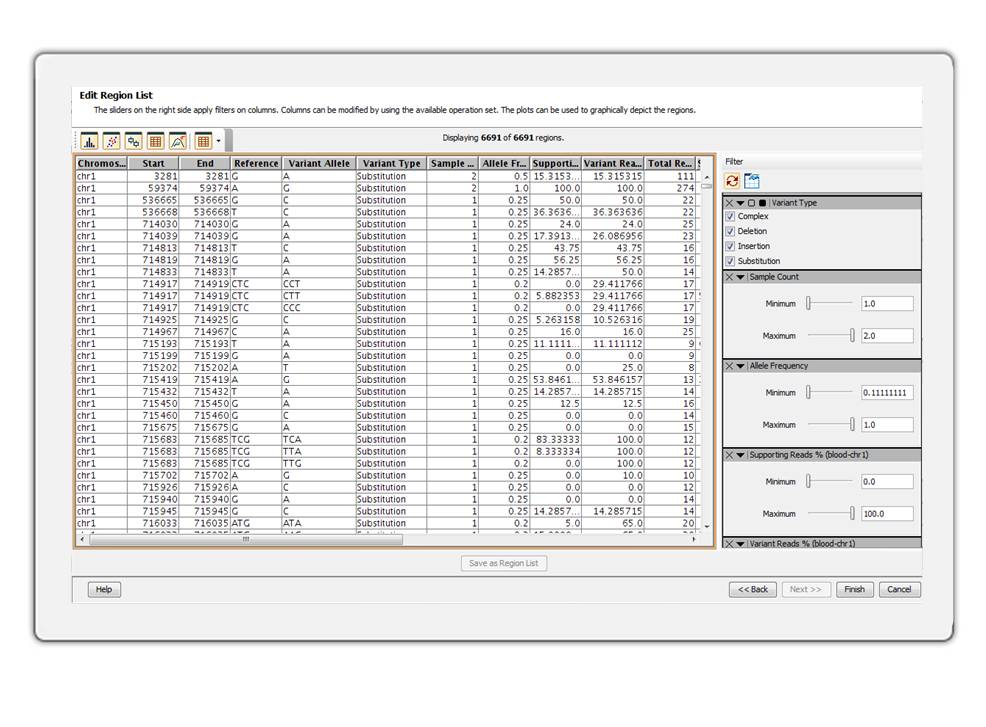
Seamlessly create and manipulate genomic region lists. Filter region lists based on different attributes.
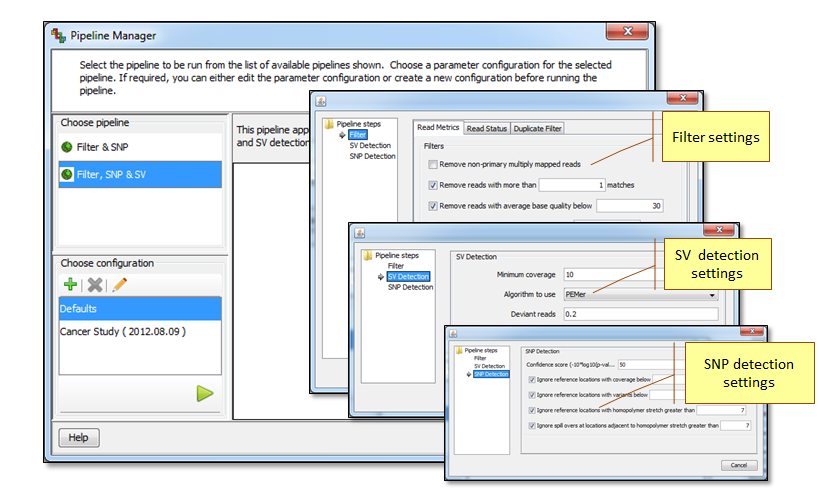
Execute one-shot pipeline for quick analysis and compute-intensive tasks using the Pipeline Manager. Also, configure pipelines or import customized pipelines using a .json file to perform reiterative tasks. Pipeline Manager also allows interaction with the user interface even as the pipelines are being executed in the background.
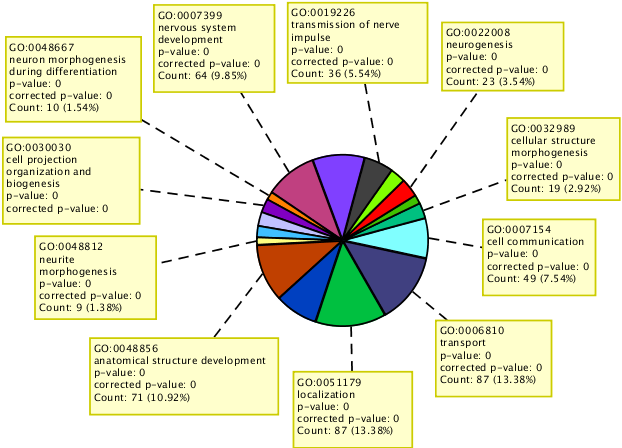
Perform GO analysis on the set of genes affected by identified variants.
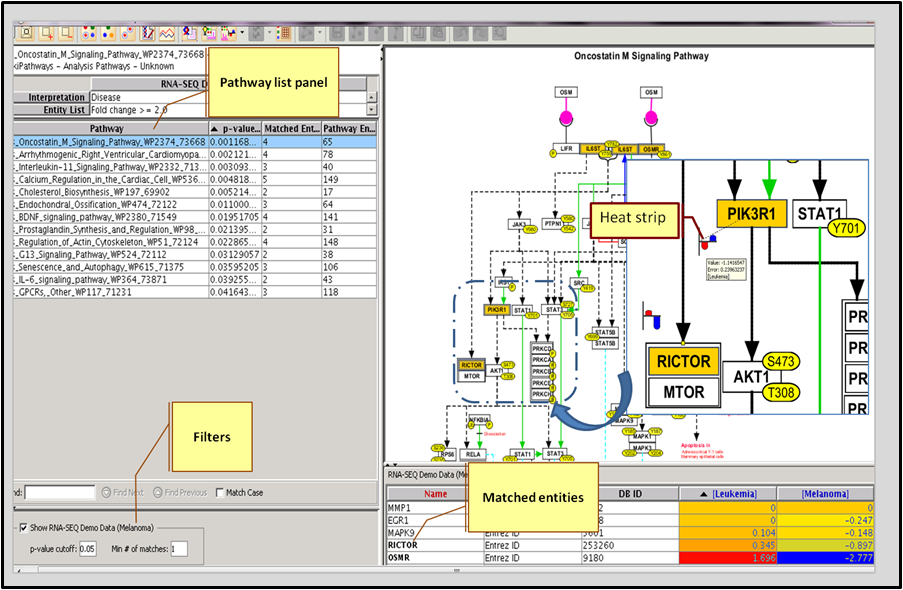
Use the packaged Interaction Database of over 2 million interactions (with supporting PubMed references) or other curated pathways to find relationships between genes. Learn more
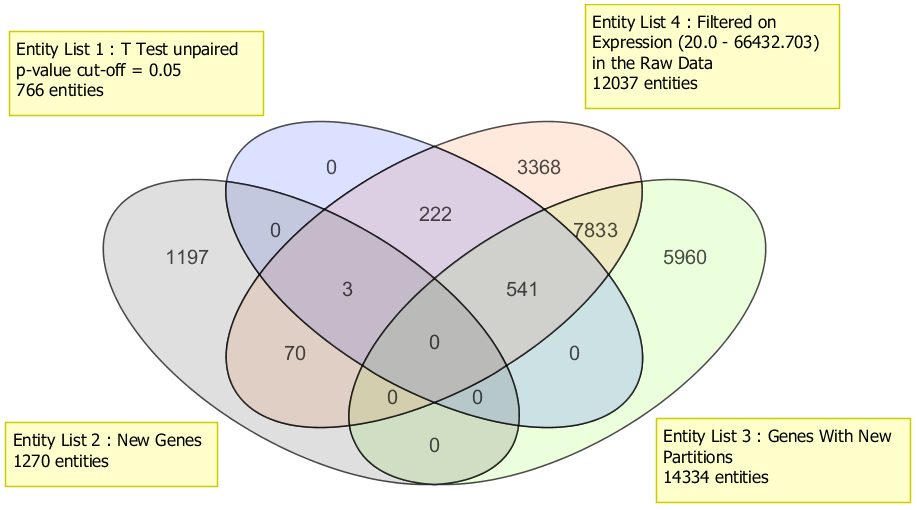
Compare different gene lists from multiple experiments and across organisms.
2018 © Strand Life Sciences Pvt Ltd. All rights reserved.